01 — The Problem
A creator agency drowning in spreadsheets
YouTube creator agencies manage revenue across dozens of creators — Adsense payouts, sponsor deals, agency fees. When all of that lives in raw CSVs, someone has to manually clean and consolidate it every single month.
The data was messy: missing revenue values, inconsistent formatting, null sponsor entries, duplicate rows. It wasn't analysis-ready — it needed hours of manual work before anyone could even ask a business question.
The goal was simple: eliminate that manual work entirely and deliver a clean, structured dataset straight into a database where it can be queried immediately.
02 — My Approach
Think before you code
Before writing a single line, I mapped out the three phases the pipeline needed to handle:
1
Ingestion — read raw creator CSVs reliably, regardless of formatting inconsistencies
2
Cleaning — handle nulls intelligently (zero for numeric fields, "No Sponsor" for missing brands), strip whitespace, standardise types
3
Loading — inject the clean data into PostgreSQL in a way that's repeatable and safe to run multiple times
03 — What I Built
A three-phase Python pipeline
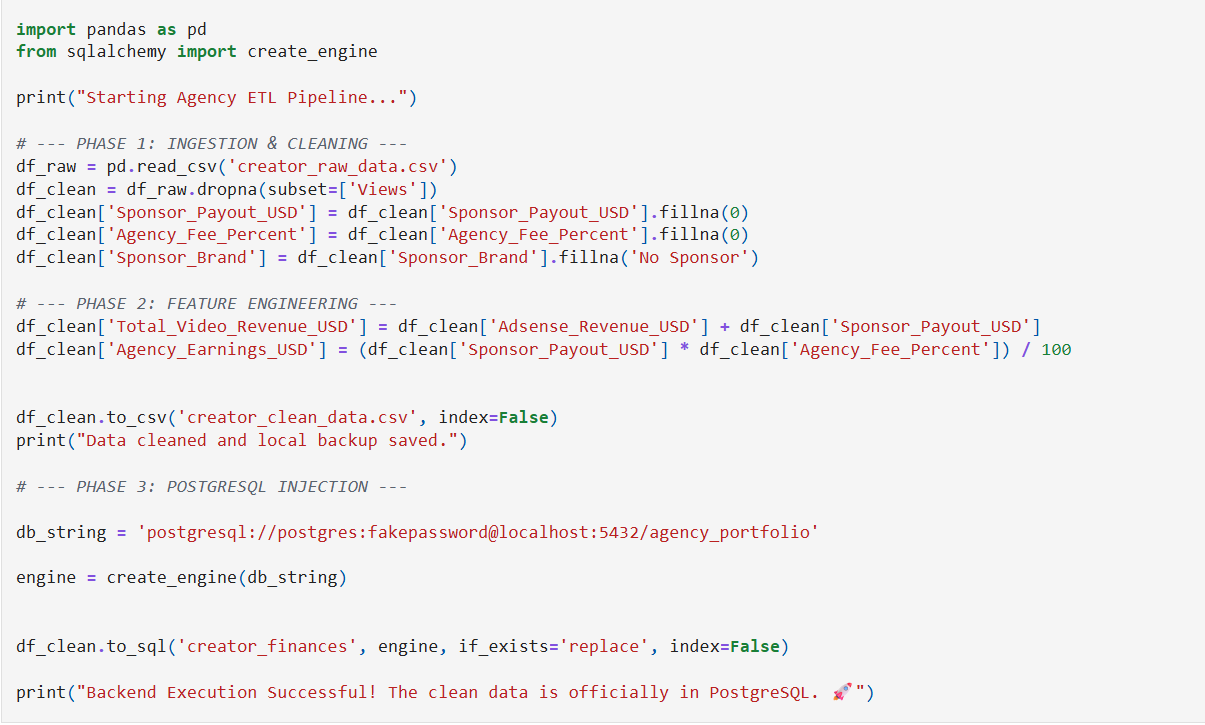
The core logic across all three phases looked like this:
# Phase 1 — Ingestion
df_raw = pd.read_csv('creator_raw_data.csv')
# Phase 2 — Cleaning
df_clean = df_raw.dropna(subset=['Views'])
df_clean['Sponsor_Payout_USD'] = df_clean['Sponsor_Payout_USD'].fillna(0)
df_clean['Sponsor_Brand'] = df_clean['Sponsor_Brand'].fillna('No Sponsor')
df_clean['Total_Revenue'] = df_clean['Adsense_Revenue_USD'] + df_clean['Sponsor_Payout_USD']
# Phase 3 — Load into PostgreSQL
engine = create_engine(db_string)
df_clean.to_sql('creator_finances', engine, if_exists='replace')
The feature engineering step was the most valuable addition — computing Total_Video_Revenue_USD and Agency_Earnings_USD meant downstream queries didn't need to recalculate these every time.
04 — Challenges
What didn't go smoothly
!
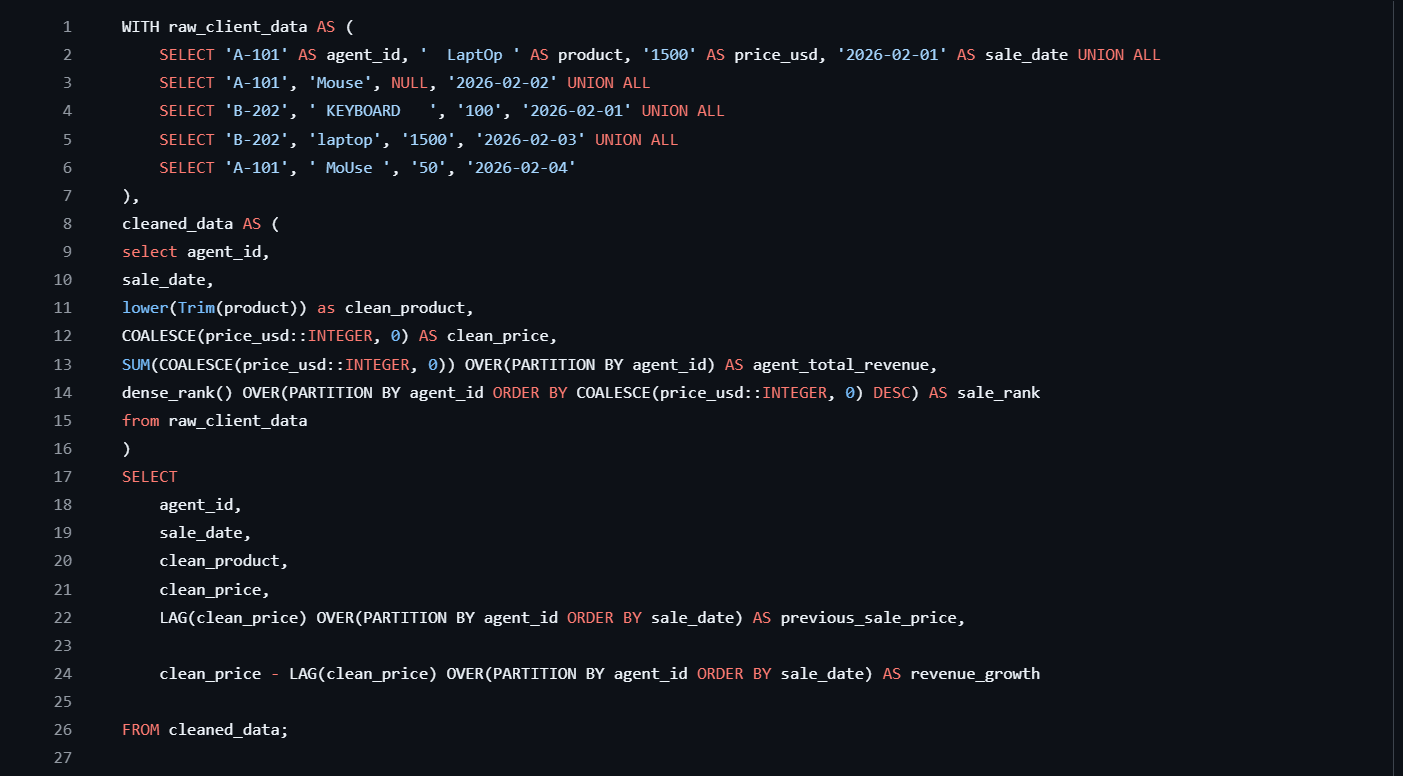
Null handling strategy — not all nulls mean the same thing. A null sponsor payout means £0, but a null view count means the row is invalid and should be dropped. Getting this logic right was critical.
!
Database connection security — the pipeline needed to handle connection failures gracefully and never expose credentials in the codebase.
!
Idempotency — using if_exists='replace' meant the pipeline could be safely re-run without duplicating data.
05 — Results
What it delivered
~0
Manual hours per month
3
Revenue streams tracked
100%
Repeatable & automated
The pipeline replaced what was previously a manual monthly process. Data now lands in PostgreSQL clean, typed correctly, and ready for any downstream query or dashboard to consume immediately.
06 — What I Learned
The real lesson
The technical skills — Pandas, SQLAlchemy, null handling — were learnable. The bigger lesson was about thinking like an engineer before thinking like an analyst.
A good pipeline isn't just one that works once. It's one that works every time, fails clearly when something goes wrong, and doesn't need someone to babysit it. That mindset shift — from "does this produce the right answer?" to "is this production-ready?" — is what this project taught me most.